This feature is only available on Chainloop’s platform paid plans.
Overview
Chainloop can leverage Large Language Models (LLMs) to evaluate evidence using natural-language prompts. This allows you to define flexible, human-readable compliance checks that go beyond what traditional rule-based policies can express. There are two approaches:- Built-in
evidence-promptpolicy — No code needed. Define a prompt directly in your workflow contract and Chainloop handles the rest. - Custom Rego policies with
chainloop.evidence_prompt— For advanced use cases where you need to combine AI analysis with programmatic logic.
Prerequisites
Before using LLM-driven policies, you need to register an AI Provider integration in your Chainloop organization. Navigate to Integrations and filter by AI Provider to see the available options:
Option 1: Using the built-in evidence-prompt policy
The simplest way to run LLM-driven evaluations is using the built-in evidence-prompt policy. It requires no Rego code — just a natural-language prompt.

prompt, which describes what the AI should analyze in the evidence.
Adding to a workflow contract
Reference theevidence-prompt policy in your workflow contract under policies.attestation, policies.materials, or both depending on what you want to evaluate.
contract.yaml
- Under
policies.attestation: the prompt runs against the full attestation envelope, useful for cross-material checks like verifying all container images come from trusted registries. - Under
policies.materials: the prompt runs against each matching material individually (e.g., each SBOM), useful for per-artifact analysis like license compliance or vulnerability assessment.
Evaluation results
Like any other policy, the evaluation results are cryptographically signed and embedded in the attestation. LLM-driven evaluations are clearly marked with an AI indicator so you can distinguish them from traditional rule-based checks.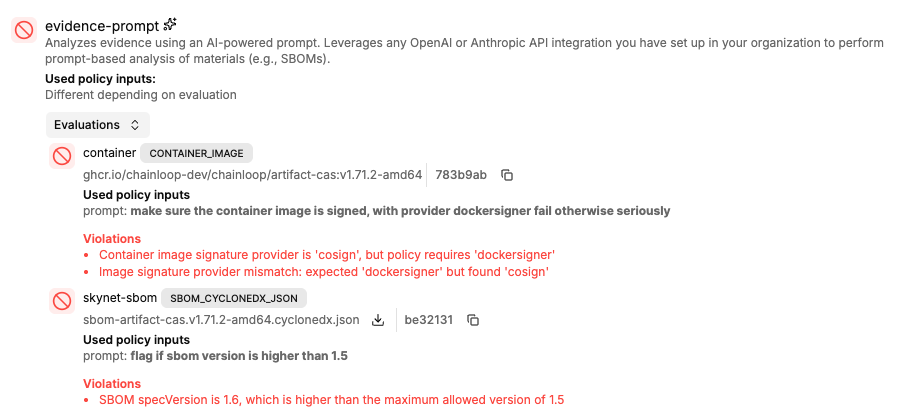
Option 2: Using chainloop.evidence_prompt in custom policies
For more control, you can call the chainloop.evidence_prompt builtin function from within a custom Rego policy. This lets you combine AI analysis with programmatic checks in a single policy.
See How to write custom policies for the full custom policy workflow.
The chainloop.evidence_prompt function
evidence(string): a CAS digest (sha256:...) or raw evidence contentprompt(string): the prompt describing what to analyze- Returns an object with
skipped(boolean) andviolations(array of strings)
Example: combining AI analysis with programmatic checks
The following policy uses the AI prompt to find license issues, then adds a programmatic check to ensure a minimum number of components exist in the SBOM:policy.rego
How it works
When a policy with an LLM prompt is evaluated during an attestation:- Chainloop extracts the relevant evidence content (the full attestation or an individual material).
- The evidence content and your prompt are sent to whichever AI provider is configured in your organization.
- The LLM analyzes the evidence according to your prompt and returns any violations it finds.
- Those violations surface in the attestation results alongside violations from any other policies.